The core of Mivvi is a fuzzy string search over a collection of known titles. Fuzzy means that typos, spelling mistakes and even minor changes don’t prevent a successful match. The Levenshtein distance measures the number of simple edits to transform one string into another. Mivvi’s algorithm is a simple linear search: each title is compared to the query and the closest one, within a reasonable distance, is used.
This isn’t quick and runtime increases linearly with the dataset: not great when the plan is to grow.
When I found a great write-up of BK-trees they seemed an ideal alternative. The concept and implementation are reassuringly simple.
My first step was benchmarking, rather than analysis. I measured the time taken to find a randomly-chosen title in a list of N titles, varying N to see how the algorithm scaled. I compared the original linear search to a BK-tree. Initial results were disappointing. The tree is faster, but not significantly.
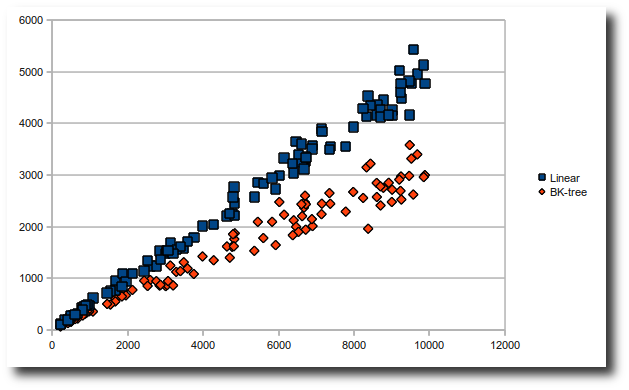
Following the classic try-then-read cycle, I paid more attention to the article. I saw that the maximum distance affects the BK-tree’s performance. For a linear search this makes no difference.
By default Mivvi allows a large edit distance to catch major changes. Restricting the maximum edit distance to 1 makes a dramatic difference.

So dramatic that a change of scale is in order:

The BK-tree’s efficiency comes from restricting the search at each node to the surrounding ring of width D, the maximum distance. The wider the ring, the more of the search space we cover. An infinite maximum distance would result in an exhaustive search.
Different values for D show the change in performance:

The lower values offer a significant improvement over a linear search. Given that the BK-tree never performed worse, I’ll adopt it. There’s a tunable parameter that I can wind down to improve results after looking at the impact on accuracy.
In future, combining a low maximum distance with a separate word-based algorithm for more distant searches may offer the best performance.